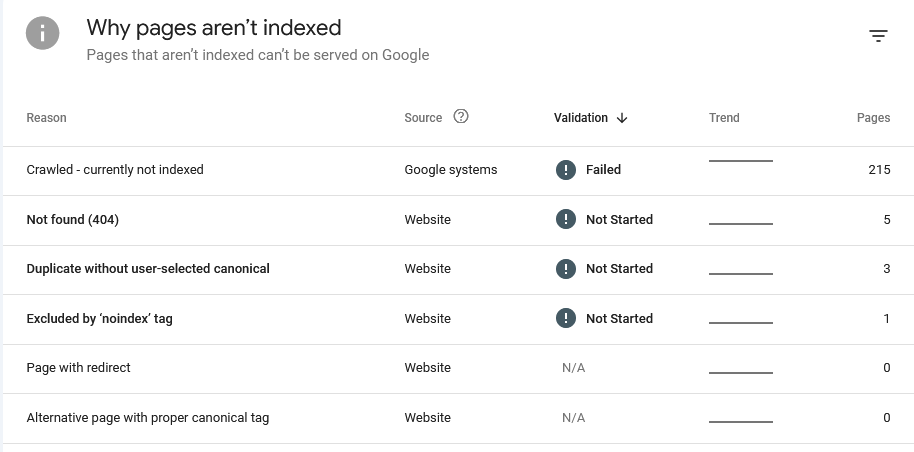
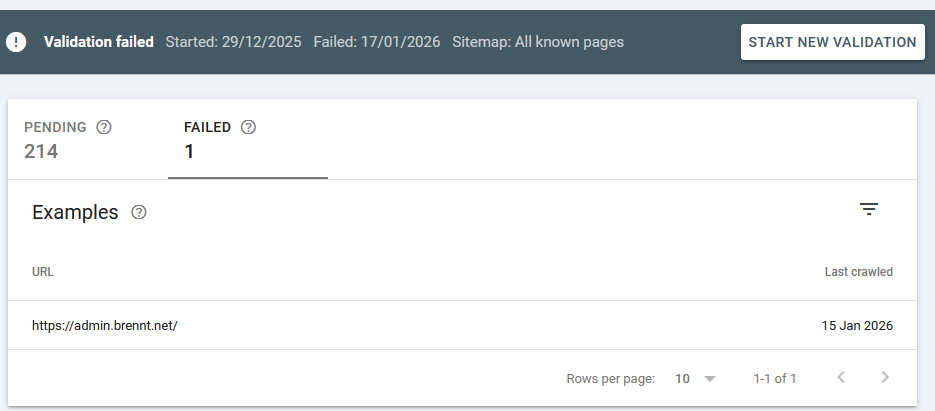
Recovering files from anonymous Docker volumes
A while ago I tried to login into my Readeck instance. Only that the login page didn't show up. Instead I was greeted by the "Create your first user" page. I created the same user I had before, with the same password. Thinking that maybe the Docker container got updated and now somehow there was a mismatch between the configured and present users. Or that some configuration variable changed. Or whatever.
I logged in with that new user, only for Readeck to show up empty. No saved articles, no tags, nothing.
Narf! Not fun at all.
What happened?
I did use Watchtower at the time to automatically update all my Docker images. So it was likely that something happened to the volume. As I store all persistent files for containers under /opt/docker for backup purposes, I checked there first. However when I checked /opt/docker/readeck I noticed that the timestamps were odd. I recently added bookmarks to Readeck, but the timestamps were months old.
Was something wrong with the volume? I searched for automatically created volumes containing an db.sqlite3 file, which is the SQLite database for Readeck.
root@dockerhost:~# find /var/lib/docker/volumes/ -type f -name db.sqlite3
/var/lib/docker/volumes/a20f45b8921e1fc4b27a64bffb4882bf2b60cd6a0828dbda94cc7a5042732a05/_data/data/db.sqlite3
/var/lib/docker/volumes/231d86a6aeb573c7d1b69a2f8ae6fb41e3e408f5e4fcb6df50ee655afd354945/_data/data/db.sqlite3
/var/lib/docker/volumes/0a92fa690e2a989987a333e7c942b29f262aab321d7e556e9a1379c98f3c81dd/_data/data/db.sqlite3
/var/lib/docker/volumes/ab3e17ca1bdb9736dc2c13c397568556795a357856db2b75f38d715b322969b0/_data/data/db.sqlite3
/var/lib/docker/volumes/29a674eb2232756fc12eb9a3446ef5160d3a56642f0069e647d2994776f9313a/_data/data/db.sqlite3
/var/lib/docker/volumes/1a51181ea17bf258144232bc9724fe5268febf10753e4b98d3a14df2e7dbf075/_data/data/db.sqlite3
/var/lib/docker/volumes/readeck_readeck-data/_data/data/db.sqlite3
/var/lib/docker/volumes/187d53ec45c6d9bf69f3a5006605a5296dbe855e21846e15c943364db87cf434/_data/data/db.sqlite3Huh? 7 anonymous and 1 named volume? But that readeck_readeck-data volume shouldn't be there. That's what /opt/docker/readeck is for.. I checked the docker compose file and yep, the volume was still defined there. Along with a totally (syntactically and semantically) wrong path. This lead to Watchtower creating random volumes when the Readeck-container was updated. Looks like I identified the root cause.
Most likely this happened when I edited the standard compose file, but didn't pay enough attention and build this error into it. Then I didn't check immediately after re-deploying the container and left it running for some weeks without using it. *sigh*
Docker, where is my data?
An ls -la on the files showed that all but one file were created around the same time with the same filesize. That one different should have my data, right?
root@dockerhost:~# find /var/lib/docker/volumes/ -type f -name db.sqlite3 -exec ls -la '{}' ';'
-rw-r--r-- 1 root root 3366912 Aug 31 2025 /var/lib/docker/volumes/a20f45b8921e1fc4b27a64bffb4882bf2b60cd6a0828dbda94cc7a5042732a05/_data/data/db.sqlite3
-rw-r--r-- 1 root root 110592 Sep 10 2025 /var/lib/docker/volumes/231d86a6aeb573c7d1b69a2f8ae6fb41e3e408f5e4fcb6df50ee655afd354945/_data/data/db.sqlite3
-rw-r--r-- 1 root root 110592 Sep 10 2025 /var/lib/docker/volumes/0a92fa690e2a989987a333e7c942b29f262aab321d7e556e9a1379c98f3c81dd/_data/data/db.sqlite3
-rw-r--r-- 1 root root 110592 Sep 10 2025 /var/lib/docker/volumes/ab3e17ca1bdb9736dc2c13c397568556795a357856db2b75f38d715b322969b0/_data/data/db.sqlite3
-rw-r--r-- 1 root root 110592 Sep 2 2025 /var/lib/docker/volumes/29a674eb2232756fc12eb9a3446ef5160d3a56642f0069e647d2994776f9313a/_data/data/db.sqlite3
-rw-r--r-- 1 root root 110592 Sep 10 2025 /var/lib/docker/volumes/1a51181ea17bf258144232bc9724fe5268febf10753e4b98d3a14df2e7dbf075/_data/data/db.sqlite3
-rw-r--r-- 1 root root 110592 Sep 10 2025 /var/lib/docker/volumes/readeck_readeck-data/_data/data/db.sqlite3
-rw-r--r-- 1 root root 110592 Sep 10 2025 /var/lib/docker/volumes/187d53ec45c6d9bf69f3a5006605a5296dbe855e21846e15c943364db87cf434/_data/data/db.sqlite3I verified that this volume is indeed belonging to Readeck by printing the config.toml as only the Readeck container uses port 7777. After all db.sqlite3 is a pretty common name.
root@dockerhost:~# cat /var/lib/docker/volumes/a20f45b8921e1fc4b27a64bffb4882bf2b60cd6a0828dbda94cc7a5042732a05/_data/config.toml
[main]
log_level = "INFO"
secret_key = "REMOVED"
data_directory = "data"
[server]
host = "0.0.0.0"
port = 7777
[database]
source = "sqlite3:data/db.sqlite3"I wanted to understand exactly what happened. So I used the following command to print out all used volume mounts inside the readeck container, with their source (local path on dockerhost) and destination (where they got mounted inside the container).
It looked the following:
root@dockerhost:~# docker container inspect readeck | jq -r '.[].Mounts[] | "\(.Source) -> \(.Destination)"'
/var/lib/docker/volumes/readeck_readeck-data/_data -> /opt/readeck
/var/lib/docker/volumes/ab3e17ca1bdb9736dc2c13c397568556795a357856db2b75f38d715b322969b0/_data -> /readeckSo anonymous volume ab3e17ca1bdb9736dc2c13c397568556795a357856db2b75f38d715b322969b0 is the currently used one and got mounted under /readeck, where /readeck is the normal path for mounting. The named volume readeck-data was mounted under /opt/readeck. Yep, I messed up completely when writting that compose file.. Even wrote /opt/docker/readeck wrong and messed up the sides of the parameter. 😅
The anonymous volume with my data a20f45b8921e1fc4b27a64bffb4882bf2b60cd6a0828dbda94cc7a5042732a05 wasn't mounted at all. No wonder my data was missing.
The solution was easy, I zipped everything under /opt/docker/readeck prior deletion, just to be safe. Then I copied everything from /var/lib/docker/volumes/a20f45b8921e1fc4b27a64bffb4882bf2b60cd6a0828dbda94cc7a5042732a05 to /opt/docker/readeck and adjusted the file ownerships.
root@dockerhost:~# cp -ar /var/lib/docker/volumes/a20f45b8921e1fc4b27a64bffb4882bf2b60cd6a0828dbda94cc7a5042732a05/* /opt/docker/readeck
root@dockerhost:~# chown readeck:readeck /opt/docker/readeck -RAfter that I fixed the compose file, deleting the named volume part and correcting the mount parts for my /opt/docker/readeck volume.
---
services:
app:
image: codeberg.org/readeck/readeck:latest
container_name: readeck
ports:
- 7777:7777
environment:
# Defines the application log level. Can be error, warn, info, debug.
- READECK_LOG_LEVEL=info
# The IP address on which Readeck listens.
- READECK_SERVER_HOST=0.0.0.0
# The TCP port on which Readeck listens. Update container port above to match (right of colon).
- READECK_SERVER_PORT=7777
# Optional, the URL prefix of Readeck.
# - READECK_SERVER_PREFIX=/
# Optional, a list of hostnames allowed in HTTP requests.
# - READECK_ALLOWED_HOSTS=readeck.example.com
volumes:
# Example with named volume under /var/lib/docker/volumes/:
# - readeck-data:/readeck
# Volume under /opt/docker/readeck
- /opt/docker/readeck/:/readeck
restart: unless-stopped
healthcheck:
test: ["CMD", "/bin/readeck", "healthcheck", "-config", "config.toml"]
interval: 30s
timeout: 2s
retries: 3A container restart and Yai! all my data is back.
I additionally verified this by looking at the mounted volume again:
root@dockerhost:~# docker container inspect readeck | jq -r '.[].Mounts[] | "\(.Source) -> \(.Destination)"'
/opt/docker/readeck -> /readeckThis looks fine!
Cleaning up
What's left? Obviously some volumes we don't need anymore which didn't get automatically deleted when the container was re-deployed. This is due to the fact that almost all volumes are created via a Docker compose file. And when a volume (even anonymous ones) are created via docker compose it automatically adds labels to the volume.
The catch? According to the documentation a docker volume prune should delete all anonymous volumes, right?
It doesn't. As this deletes far too less volumes.
root@dockerhost:~# docker volume prune
WARNING! This will remove anonymous local volumes not used by at least one container.
Are you sure you want to continue? [y/N] y
Deleted Volumes:
0ffc2596aab0b5d7f55081cfcd82c04cb06f3048fcb98b1eae2a84030204fe71
b2309b6bd7409528a863cc1ac50ac30b70fcdccfa511e7c0b321660955fd7743
eb87c77fde8b4af28c2e20a97da4c4ca96366ae13b24f8808d76927206722a20
3631579e7175830579763bc090a6e3447ff2a2b3b3fe837df40665d8549aee93
9e95bb31bafe0c5fd671c1da565306863d610e6155e1652e29e5921a49bc3a1c
80803ccaf0832c7a224e457edf3b0ba3e22179b0be06e2e3e00be7e52559b26d
3595952fe6af563d3afa6f7d56fe3bf0b7dfe8d008e1bb148fade0207a1f319a
585cee8e70d51d051049e4734e8a45d028a2020cf76e6605e33f6a4b68e9f5cd
Total reclaimed space: 0B
Well, the thing is: Volumes with labels are NOT treated as anonymous volumes by docker volume prune. Even if their names imply otherwise. The labels com.docker.compose.project, com.docker.compose.version and com.docker.compose.volume are added automatically.
root@portainer:/var/lib/docker/volumes# docker volume inspect firefly-iii_firefly_iii_upload
[
{
"CreatedAt": "2025-08-14T18:29:37+02:00",
"Driver": "local",
"Labels": {
"com.docker.compose.project": "firefly-iii",
"com.docker.compose.version": "",
"com.docker.compose.volume": "firefly_iii_upload"
},
"Mountpoint": "/var/lib/docker/volumes/firefly-iii_firefly_iii_upload/_data",
"Name": "firefly-iii_firefly_iii_upload",
"Options": null,
"Scope": "local"
}
]Hence we need to add -a or --all in order to delete unused, anonymous volumes with labels too.
root@dockerhost:~# docker volume prune -a
WARNING! This will remove all local volumes not used by at least one container.
Are you sure you want to continue? [y/N] y
Deleted Volumes:
b902bad86954afb635992b32c4f382f08d4183c8ef9ce27ddbac03731e0405fe
0f16bb90cfb343b78fcbc7c8deec1cd2de3ee6e68f949b2b2bdc53ed3a7066e9
187d53ec45c6d9bf69f3a5006605a5296dbe855e21846e15c943364db87cf434
231d86a6aeb573c7d1b69a2f8ae6fb41e3e408f5e4fcb6df50ee655afd354945
818bd6aeaf630f00565d4ab56cdefffd6e68e42b8a75250d0573ba2f30cc5f30
939b33eb1a0ff229a1b69da08471c9fd4958d46544ddaeceaf6c81dd4d467619
362344bb946409778ae17f586bd94ac3468057a83ea15fd5d664fe820b6987bb
0b75f0001bc41866736fca25052fb7de92ac12bb9a836cdc6b30dd0cfed30bdf
93fc5df32a27ded4dc82fa90c8d0158ebf31149c7f3c2be2a99641b2eb7d3a57
d55795ba82c823b2f56d0ece2b26ab8f441df58707ca2f9f5dff9636ec3fccfd
0de81441bf39b5df40e022297d124fb8895d4a9b0b0488134820f33d03d12060
1a51181ea17bf258144232bc9724fe5268febf10753e4b98d3a14df2e7dbf075
1f123a21114fa7b43b75fdbcf03e55ecc0852a013d1e3b8db9c9321cc8b14a36
29a674eb2232756fc12eb9a3446ef5160d3a56642f0069e647d2994776f9313a
38252cf2f07379d3af44cbe8f9694b20083cd804312816357fc0b188455fa295
7f0a2646cde46c3aca1affe7c145130129027825437472b12926287f3a641301
ab3e17ca1bdb9736dc2c13c397568556795a357856db2b75f38d715b322969b0
b4f8a04c56d6f222691d73e057153f7e8b45bd47d2b7956b9623dd04c33e33dc
readeck_readeck-data
a20f45b8921e1fc4b27a64bffb4882bf2b60cd6a0828dbda94cc7a5042732a05
0a92fa690e2a989987a333e7c942b29f262aab321d7e556e9a1379c98f3c81dd
67c4199a258f16362cc456003ea269a6e5bfb51fa2354665766e62ca93616487
85f7700515ede9dabeeaf4edd64509dbfed8988a14b37cf62d6d923934a6f8db
Total reclaimed space: 2.433GBThe Labels also explain why there were so many unused anonymous volumes. As apparently neither Watchtower nor Portainer seem to use docker volume prune -a when doing their maintenance chores. Which is a decision I can understand, but find annoying anyway.
Dockers stance is: Named volumes must be deleted manually (or by using -a/--all), as they have been named for a reason and, most likely, contain data which is persistent and therefore important. Same for volumes with labels.
Something I always forget
Let's say we want to execute a command for every container we have. For this we need the container name, or ID - but the names are easier to use for us humans and make more sense in outputs, etc. Also the IDs will change after certain operations. Making it impossible to trace back what action had been done to which container.
Getting the containers names should be easy with awk, right? Well, no. Sadly docker container ls doesn't use tabs or the like which we could easily use as the field separator for awk. Hence something like docker container ls | awk -F'\t' '{print $7}' doesn't work and won't print out any information at all.
The IDs are easily retrievable with: docker container ls | awk '{print $1}' | tail -n +2
Luckily Docker supports the --format parameter for most of its commands. This takes simple Go templates and we can use JSON syntax in there.
Knowing this, we can retrieve all container names easily via the following command:
root@dockerhost:~# docker container ls --format "{{.Names}}"
n8n
metube
stirling-pdf
termix
homepage
readeck
nebula-sync
[...] (Click to enlarge)
(Click to enlarge)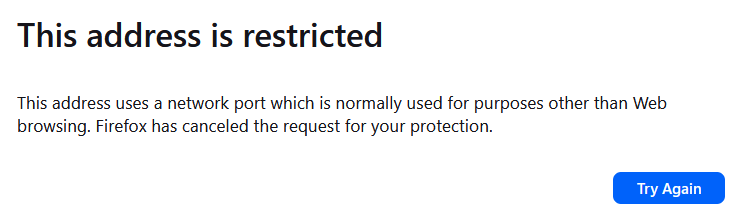 Huh? What? I use all kinds of strange ports in my home network and never got that error message.
Huh? What? I use all kinds of strange ports in my home network and never got that error message.
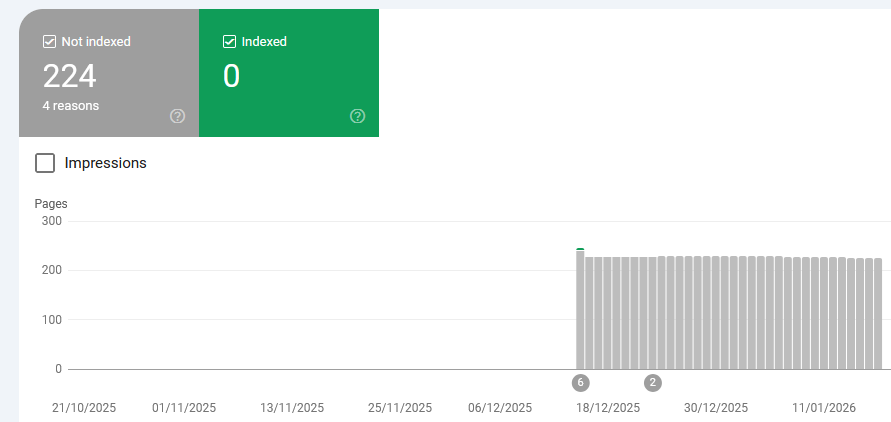
 Just for the record, this is my robots.txt. As plain, boring and simple as it can be.
Just for the record, this is my robots.txt. As plain, boring and simple as it can be.